Deep Mind's Neural Scene Rendering System Predicts 3D Surroundings Using Its Own Sensors
Google's Deepmind introduced the Generative Query Network (GQN), a framework within which machines learn to perceive their surroundings by training only on data obtained by themselves as they move around scenes.
Much like infants and animals, the GQN learns by trying to make sense of its observations of the world around it. In doing so, the GQN learns about plausible scenes and their geometrical properties, without any human labelling of the contents of scenes.
Human brains understand a visual scene using "data" based on prior knowledge and to make inferences that go far beyond the patterns of light that hit our retinas. For example, when entering a room for the first time, you instantly recognise the items it contains and where they are positioned. If you see three legs of a table, you will infer that there is probably a fourth leg with the same shape and colour hidden from view. Even if you can't see everything in the room, you'll likely be able to sketch its layout, or imagine what it looks like from another perspective.
These visual and cognitive tasks are seemingly effortless to humans, but they represent a significant challenge to our artificial systems. Today, visual recognition systems are using large datasets of annotated images produced by humans. Acquiring this data is a costly and time-consuming process, requiring individuals to label every aspect of every object in each scene in the dataset. As a result, often only a small subset of a scene's overall contents is captured, which limits the artificial vision systems trained on that data.
To train a computer to 'recognize' elements of a scene supplied by its visual sensors, computer scientists typically use millions of images painstakingly labeled by humans. Deepmoing researhcers developed an artificial vision system, dubbed the Generative Query Network (GQN), that has no need for such labeled data. Instead, the GQN first uses images taken from different viewpoints and creates an abstract description of the scene, learning its essentials. Next, on the basis of this representation, the network predicts what the scene would look like from a new, arbitrary viewpoint.
The GQN model is composed of two parts: a representation network and a generation network. The representation network takes the agent's observations as its input and produces a representation (a vector) which describes the underlying scene. The generation network then predicts ('imagines') the scene from a previously unobserved viewpoint.
The representation network does not know which viewpoints the generation network will be asked to predict, so it must find an efficient way of describing the true layout of the scene as accurately as possible. It does this by capturing the most important elements, such as object positions, colours and the room layout, in a concise distributed representation. During training, the generator learns about typical objects, features, relationships and regularities in the environment. This shared set of 'concepts' enables the representation network to describe the scene in a highly compressed, abstract manner, leaving it to the generation network to fill in the details where necessary. For instance, the representation network will succinctly represent 'blue cube' as a small set of numbers and the generation network will know how that manifests itself as pixels from a particular viewpoint.
Deepming researchers performed controlled experiments on the GQN in a collection of procedurally-generated environments in a simulated 3D world, containing multiple objects in random positions, colours, shapes and textures, with randomised light sources and heavy occlusion. After training on these environments, they used GQN's representation network to form representations of new, previously unobserved scenes. The experiments showed that the GQN's generation network can 'imagine' previously unobserved scenes from new viewpoints with remarkable precision. When given a scene representation and new camera viewpoints, it generates sharp images without any prior specification of the laws of perspective, occlusion, or lighting. The generation network is therefore an approximate renderer that is learned from data:
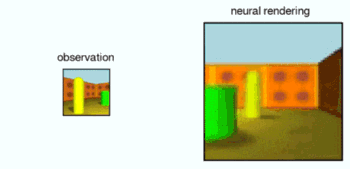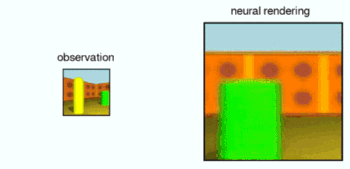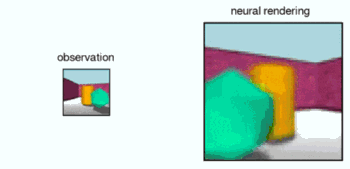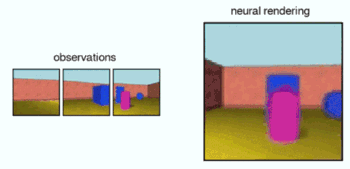
In addition, the GQN's representation network can learn to count, localise and classify objects without any object-level labels. Even though its representation can be very small, the GQN's predictions at query viewpoints are highly accurate and almost indistinguishable from ground-truth. This implies that the representation network perceives accurately, for instance identifying the precise configuration of blocks that make up the scenes below:
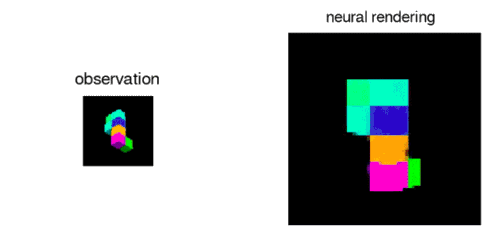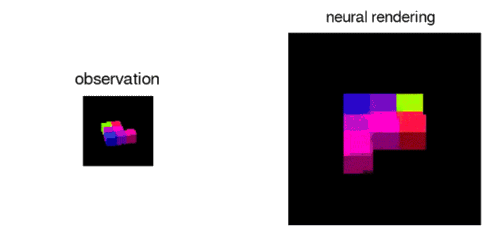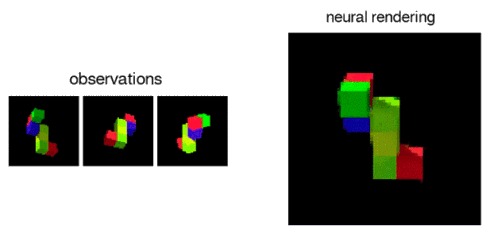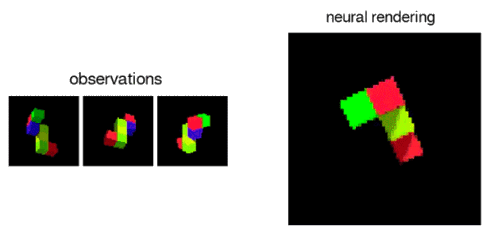
The GQN can also represent, measure and reduce uncertainty. It is capable of accounting for uncertainty in its beliefs about a scene even when its contents are not fully visible, and it can combine multiple partial views of a scene to form a coherent whole.
Deepmind said that their method still has many limitations when compared to more traditional computer vision techniques, and has currently only been trained to work on synthetic scenes. However, as new sources of data become available and advances are made in hardware capabilities, the researchers expect to be able to investigate the application of the GQN framework to higher resolution images of real scenes. In future work, it will also be important to explore the application of GQNs to broader aspects of scene understanding, for example by querying across space and time to learn a common sense notion of physics and movement, as well as applications in virtual and augmented reality.