
Intel Redesigns The Xeon Phi Chip For Supercomputers
Intel on Tuesday promised big performance and power improvements with the redesigned Xeon Phi chip called "Knights Landing", which is expected to ship next year or in 2015.
During the Supercomputing Conference (SC'13), Intel unveiled how the next generation Intel Xeon Phi product (codenamed "Knights Landing"), available as a host processor, will fit into standard rack architectures and run applications entirely natively instead of requiring data to be offloaded to the coprocessor.
That is a big change from the current Xeon Phi chip, code-named Knights Corner, which is available only as a co-processor and requires a server CPU like a Xeon E5 to host applications and run an OS.
Knights Landing will reduce programming complexity and eliminate "offloading" of the data, thus improving performance and decreasing latencies caused by memory, PCIe and networking.
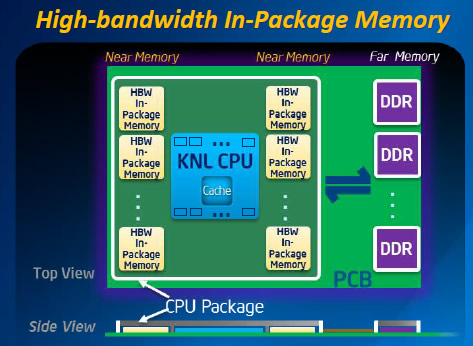
Knights Landing will also offer developers three memory options to optimize performance. Unlike other Exascale concepts requiring programmers to develop code specific to one machine, Intel says its new Intel Xeon Phi processors will provide the simplicity of standard memory programming models.
Knights Landing will also support single-threaded applications. Accelerator chips today focus mostly on highly parallel applications, leaving single threaded applications hanging to be processed by other hardware units.
Knights Landing will be made using the 14nm manufacturing process. The first 14-nm chips are expected to reach PCs in the second half of this year, and Knights Landing could follow.
In addition, Intel and Fujitsu recently announced an initiative that could potentially replace a computer's electrical wiring with fiber optic links to carry Ethernet or PCI Express traffic over an Intel Silicon Photonics link. This enables Intel Xeon Phi coprocessors to be installed in an expansion box, separated from host Intel Xeon processors, but function as if they were still located on the motherboard. This allows for much higher density of installed coprocessors and scaling the computer capacity without affecting host server operations.
Data intensive applications have been part of the HPC industry from its earliest days, and the performance of today's systems and parallel software tools have made it possible to create larger and more complex simulations. However, with unstructured data accounting for 80 percent of all data, and growing 15 times faster than other data, the industry is looking to tap into all of this information to uncover valuable insight.
Intel is addressing this need with the Intel HPC Distribution for Apache Hadoop software (Intel HPC Distribution) that combines the Intel Distribution for Apache Hadoop software with Intel Enterprise Edition of Lustre software to deliver a solution for storing and processing large data sets. This combination allows users to run their MapReduce applications, without change, directly on shared, fast Lustre-powered storage, making it fast, scalable and easy to manage.
The Intel Cloud Edition for Lustre software is a scalable, parallel file system that is available through the Amazon Web Services Marketplace and allows users to pay-as-you go to maximize storage performance and cost effectiveness. The software is suited for dynamic applications, including simulation and prototyping. In the case of unplanned work that exceeds a user's on-premise compute or storage performance, the software can be used for cloud bursting HPC workloads to quickly provision the infrastructure needed before moving the work into the cloud.
Advanced HPC, Aeon Computing, ATIPA, Boston Ltd., Colfax International, E4 Computer Engineering, NOVATTE and System Fabric Works announced pre-configured and validated hardware and software solutions featuring the Intel Enterprise Edition for Lustre, at SC'13.
That is a big change from the current Xeon Phi chip, code-named Knights Corner, which is available only as a co-processor and requires a server CPU like a Xeon E5 to host applications and run an OS.
Knights Landing will reduce programming complexity and eliminate "offloading" of the data, thus improving performance and decreasing latencies caused by memory, PCIe and networking.
Knights Landing will also offer developers three memory options to optimize performance. Unlike other Exascale concepts requiring programmers to develop code specific to one machine, Intel says its new Intel Xeon Phi processors will provide the simplicity of standard memory programming models.
Knights Landing will also support single-threaded applications. Accelerator chips today focus mostly on highly parallel applications, leaving single threaded applications hanging to be processed by other hardware units.
Knights Landing will be made using the 14nm manufacturing process. The first 14-nm chips are expected to reach PCs in the second half of this year, and Knights Landing could follow.
In addition, Intel and Fujitsu recently announced an initiative that could potentially replace a computer's electrical wiring with fiber optic links to carry Ethernet or PCI Express traffic over an Intel Silicon Photonics link. This enables Intel Xeon Phi coprocessors to be installed in an expansion box, separated from host Intel Xeon processors, but function as if they were still located on the motherboard. This allows for much higher density of installed coprocessors and scaling the computer capacity without affecting host server operations.
Data intensive applications have been part of the HPC industry from its earliest days, and the performance of today's systems and parallel software tools have made it possible to create larger and more complex simulations. However, with unstructured data accounting for 80 percent of all data, and growing 15 times faster than other data, the industry is looking to tap into all of this information to uncover valuable insight.
Intel is addressing this need with the Intel HPC Distribution for Apache Hadoop software (Intel HPC Distribution) that combines the Intel Distribution for Apache Hadoop software with Intel Enterprise Edition of Lustre software to deliver a solution for storing and processing large data sets. This combination allows users to run their MapReduce applications, without change, directly on shared, fast Lustre-powered storage, making it fast, scalable and easy to manage.
The Intel Cloud Edition for Lustre software is a scalable, parallel file system that is available through the Amazon Web Services Marketplace and allows users to pay-as-you go to maximize storage performance and cost effectiveness. The software is suited for dynamic applications, including simulation and prototyping. In the case of unplanned work that exceeds a user's on-premise compute or storage performance, the software can be used for cloud bursting HPC workloads to quickly provision the infrastructure needed before moving the work into the cloud.
Advanced HPC, Aeon Computing, ATIPA, Boston Ltd., Colfax International, E4 Computer Engineering, NOVATTE and System Fabric Works announced pre-configured and validated hardware and software solutions featuring the Intel Enterprise Edition for Lustre, at SC'13.




















