
Intel Reveals Architecture Details of Intel Xeon Phi Co-Processor
During HotChips symposium, George Chrysos, the leading architect of Intel Xeon Phi co-processor (codename Knights Corner) shared the new architecture details of upcoming Intel's HPC powerhouse.
The Intel MIC Architecture specifically targets highly parallel technical applications in physics, chemistry, biology and financial services - so Examples include weather prediction and climate modeling, fluid dynamics, quantum chromo-dynamics, protein folding, genetics, and options modeling.
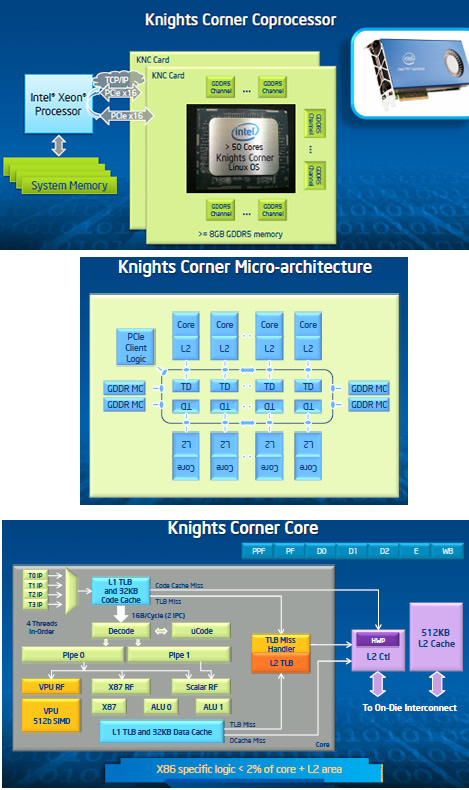
Intel Xeon Phi co-processor based on Intel Mani Integrated Core architecture will deliver the combination of high performance per watt with the ability to re-use the existing code and applications without necessity of re-writing them.
Knights Corner does not require the workloads to be re-written in a new programming language, or require a programmer to cope with a software-managed memory coherency and consistency model. From a programmer's standpoint, the architecture is simply a multi-core processor. Knights Corner runs a standard full service OS; it is a networked node that you can telnet into or communicate to via MPI or sockets programming. Fortran, C, C++ code can be compiled and run correctly on the coprocessor. The OpenMP threading library is supported, and multiple MPI tasks can run simultaneously. VTune can be used for performance characterization and tuning, and the standard Intel debuggers, compilers and libraries are available.
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology.
 To optimize the architecture for performance/watt of highly parallel HPC workloads Intel made three architectural investments:
To optimize the architecture for performance/watt of highly parallel HPC workloads Intel made three architectural investments:
- Intel built cores that are smaller than the Intel Xeon processor cores. The Knights Corner cores do less speculative work than these cores. Doing large amounts of speculative instruction processing is a great way to speed up a single thread of execution, but sometimes the speculative work is aborted and does not contribute to program progress. When there are no other threads (or processes) around, this is the right tradeoff, but when there are an abundance of threads, then instead of doing speculative work for a single thread, Intel simply chooses another thread that has instructions ready to go. The Knights Corner cores support 4 thread contexts and execute instructions in program order. Also, many micro-architectural choices were made by Intel to optimize the cores specifically for HPC workloads. Some of the design decisions made were: 1) building the L1 data cache to do both a 512b load and a 512b store per cycle, 2) adding a large L2 TLB, 3) providing an ample 512KB L2 cache per core, and 4) adding a hardware pre-fetcher. In total the design choices Intel engineers claim they made improved Spec CPU FP 2006 by more than 80% per core, per cycle.
- Intel also introduced the widest SIMD instruction set offered by the company to date, at 512-bits. In highly parallel programs, there are frequently inner loops that step regularly through memory, and perform the same math operations repeatedly. When these loops are assembled with traditional scalar instructions, the core incurs energy overhead for processing each instruction (fetching, decoding, reading the register file and the data cache, tracking dependencies, etc). SIMD amortizes that cost by doing all of the bookkeeping once and performing many math operations in just one instruction. In Knights Corner, a single vector floating point multiply-add (vfma) instruction will perform 32 single-precision or 16 double-precision operations. The wide SIMD instructions allow Intel to offer very high FLOP rates for computationally dense workloads under a constrained power budget. Wider SIMD can be challenging for an auto-vectorizing compiler or even an assembly programmer to use efficiently. The wider the SIMD, the more challenging it is to use all of the parallel ALUs. To mitigate this, the Knights Corner SIMD instruction set supports several new instruction set features. These are 1) mask registers, 2) gather/scatter, and 3) extended math unit operations. Mask registers allow for predicated execution per ALU, which supports vectorization across short conditional branches and supports efficient software pipelining. Gather/scatter instructions are vector loads and stores that are used when the memory address access patterns are not stride-1, but more irregular. To avoid serializing the code in such regions, gather and scatter instructions are supported. The extended math unit operations allow for high performance vectorized transcendental operations: square-root, reciprocal, logarithm and power. In total the wide SIMD instruction set is a great match for highly parallel programs.
- To support more than 50 cores, Intel built a scalable high bandwidth interconnect and memory subsystem. The on-die interconnect is a high bandwidth bi-directional ring topology which connects the cores to one another as well as to many GDDR5 memory controllers. Intel placed the memory controllers symmetrically on the ring topology to avoid hot-spots and provide a smooth BW response. The company also introduced a vector streaming store instruction that reduces the need to use memory BW when writing output-only arrays to memory.
On top of all of that, Intel put its power management technology into Knights Corner so that when individual cores are idle, or Knights Corner is not processing anything, it reduces its power consumption proportionately.
Intel Xeon Phi co-processor based on Intel Mani Integrated Core architecture will deliver the combination of high performance per watt with the ability to re-use the existing code and applications without necessity of re-writing them.
Knights Corner does not require the workloads to be re-written in a new programming language, or require a programmer to cope with a software-managed memory coherency and consistency model. From a programmer's standpoint, the architecture is simply a multi-core processor. Knights Corner runs a standard full service OS; it is a networked node that you can telnet into or communicate to via MPI or sockets programming. Fortran, C, C++ code can be compiled and run correctly on the coprocessor. The OpenMP threading library is supported, and multiple MPI tasks can run simultaneously. VTune can be used for performance characterization and tuning, and the standard Intel debuggers, compilers and libraries are available.
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology.
To optimize the architecture for performance/watt of highly parallel HPC workloads Intel made three architectural investments:
- Intel built cores that are smaller than the Intel Xeon processor cores. The Knights Corner cores do less speculative work than these cores. Doing large amounts of speculative instruction processing is a great way to speed up a single thread of execution, but sometimes the speculative work is aborted and does not contribute to program progress. When there are no other threads (or processes) around, this is the right tradeoff, but when there are an abundance of threads, then instead of doing speculative work for a single thread, Intel simply chooses another thread that has instructions ready to go. The Knights Corner cores support 4 thread contexts and execute instructions in program order. Also, many micro-architectural choices were made by Intel to optimize the cores specifically for HPC workloads. Some of the design decisions made were: 1) building the L1 data cache to do both a 512b load and a 512b store per cycle, 2) adding a large L2 TLB, 3) providing an ample 512KB L2 cache per core, and 4) adding a hardware pre-fetcher. In total the design choices Intel engineers claim they made improved Spec CPU FP 2006 by more than 80% per core, per cycle.
- Intel also introduced the widest SIMD instruction set offered by the company to date, at 512-bits. In highly parallel programs, there are frequently inner loops that step regularly through memory, and perform the same math operations repeatedly. When these loops are assembled with traditional scalar instructions, the core incurs energy overhead for processing each instruction (fetching, decoding, reading the register file and the data cache, tracking dependencies, etc). SIMD amortizes that cost by doing all of the bookkeeping once and performing many math operations in just one instruction. In Knights Corner, a single vector floating point multiply-add (vfma) instruction will perform 32 single-precision or 16 double-precision operations. The wide SIMD instructions allow Intel to offer very high FLOP rates for computationally dense workloads under a constrained power budget. Wider SIMD can be challenging for an auto-vectorizing compiler or even an assembly programmer to use efficiently. The wider the SIMD, the more challenging it is to use all of the parallel ALUs. To mitigate this, the Knights Corner SIMD instruction set supports several new instruction set features. These are 1) mask registers, 2) gather/scatter, and 3) extended math unit operations. Mask registers allow for predicated execution per ALU, which supports vectorization across short conditional branches and supports efficient software pipelining. Gather/scatter instructions are vector loads and stores that are used when the memory address access patterns are not stride-1, but more irregular. To avoid serializing the code in such regions, gather and scatter instructions are supported. The extended math unit operations allow for high performance vectorized transcendental operations: square-root, reciprocal, logarithm and power. In total the wide SIMD instruction set is a great match for highly parallel programs.
- To support more than 50 cores, Intel built a scalable high bandwidth interconnect and memory subsystem. The on-die interconnect is a high bandwidth bi-directional ring topology which connects the cores to one another as well as to many GDDR5 memory controllers. Intel placed the memory controllers symmetrically on the ring topology to avoid hot-spots and provide a smooth BW response. The company also introduced a vector streaming store instruction that reduces the need to use memory BW when writing output-only arrays to memory.
On top of all of that, Intel put its power management technology into Knights Corner so that when individual cores are idle, or Knights Corner is not processing anything, it reduces its power consumption proportionately.




















