ARM Introduces Cortex-A76 CPU, Mali-G76 GPU and Mali-V76 VPU For Even Faster Smartphones and Windows Devices
Mobile processor designer Arm will make your Android phone -- and maybe your ultralight Windows laptop -- to run faster with the a new chip generation, the Cortex-A75.
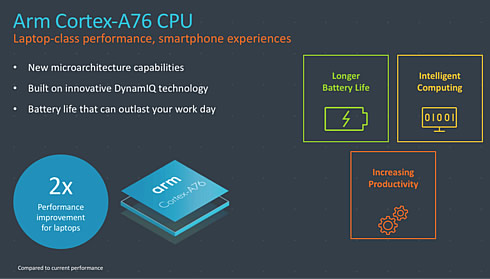
Arriving in Android smartphones in 2019, the new Arm Cortex-A76 CPU, based on DynamIQ technology, promises to deliver laptop-class performance while maintaining the power efficiency of a smartphone. This technololgy has been already appied to the Windows10 Always-Connected PCs with integrated Arm-based SoCs from Qualcomm, which deliver 20-plus hours of battery life,along with LTE connectivity and access to the Windows app ecosystem.
The A76 packs up to 2-Mbytes L2 cache, 4-Mbytes L3, and running at more than 3 GHz in a 7-nm node. It aims to deliver 90% of the Specint2006 performance of an Intel mobile Skylake chip with one-fourth the area and half the power - or roughly the same performance in thermally constrained systems.
Compared to an A72 core at 10 nm, a 7-nm A76 should deliver 35% more performance or use 40% less power. That's a step up from 15% to 25% increases that Arm typically delivers with annual core upgrades. In its day, the A72 delivered about 75% of the performance of Intel's mobile Broadwell processors.
The comparisons are based on CPUs running at similar frequencies, since Intel's chips typically support higher frequencies than Arm's cores.
The A76 aims to expand Arm's dominance in smartphones into laptops with 4+4 A76/A55 configurations sporting large caches.
The Cortex-A76 is also said to deliver 4x compute performance improvements for AI/ML at the edge, enabling responsive, secure experiences on PCs and smartphones.
"We think we've turned a corner relative to the overall performance curve," Rene Haas, president of Arm's intellectual property group, said at a press conference Thursday in San Francisco. He promised "laptop-class performance" and said it should compete with Intel's high-end Core i7 models.
Microarchitectural improvements are included in the Cortex-A76 to increase the performance, through instruction per cycle uplift or deeper memory level parallelism.
Some of the key enhancements include:
- Decoupled branch prediction and instruction fetch: Built to hide latency at high bandwidth, the in-order Cortex-A76 front-end is able to fetch 4 to 8 instructions per cycle, using multi-level branch target caches and hybrid indirect predictor to sustain the maximum throughput.
- A wider machine: Cortex-A76 is Arm's first 4-wide decode core, increasing the maximum instruction per cycle capability. Up to 8 operations per cycle can then be dispatched to the out-of-order core, supporting a wider area-/power-optimized instruction window.
- More integer and vector execution throughput: Quad-issue integer units are integrated in the core including 3x simple ALU and 1x multi-cycle integer. Moreover, Cortex-A76 supports dual-issue native 16B (128-bit) vector and floating-point units, twice the throughput of any previous Arm CPU. Vitally, it can deliver the 4x ML performance improvements we mentioned earlier.
- Enhanced memory system: The full cache hierarchy is co-optimized for latency and bandwidth, with a sophisticated 4th generation prefetcher, deep memory-level parallelism.


Along with the new suite of system IP, Arm offers POP technology that supports Cortex-A76, and its LITTLE core companion Cortex-A55, for various process technologies. The Cortex-A76 POP IP for TSMC 16FFC delivers the fastest performance in one of the most cost-effective process technologies available. For those looking for leading-edge process technologies and targeting premium and high-end applications, the Cortex-A76 and Cortex-A55 POP IPs for TSMC 7FF also will be available by Q4 2017.
Arm claims that the latest 7-nm nodes will only deliver 2% to 3% more speed than the 16-nm node.
The company also announced two accompanying chips, the Mali-G76 graphics processor and the Mali-V76 video chip.
Mali-G76
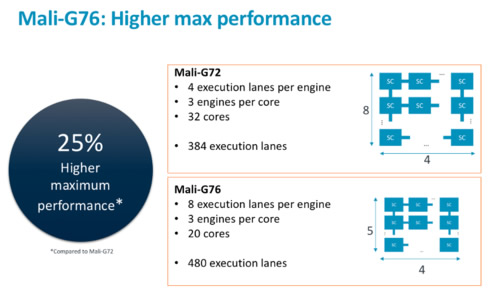
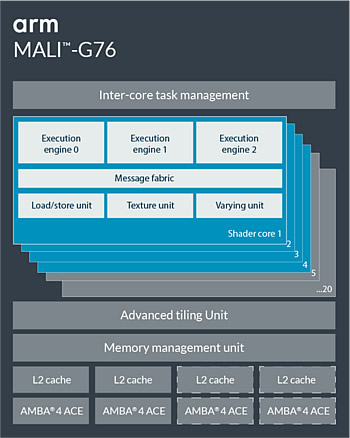
The Mali-G76, built on the Bifrost architecture, can be configured with up to 20 shader cores and an L2 cache configurable from 512 Kbytes to 4 Mbytes. Each shader sports three execution engines.
The Mali G76 is delivering 30 percent more efficiency and performance density. Of course, no new GPU worth its salt would be hitting the shelves these days without packing some serious Machine Learning punch, and Mali-G76 can deliver up to 2.7x ML improvements when compared to Mali-G72.

These generational enhancements provide developers with more performance headroom to bring more high-end gaming titles to mobile app ecosystems and enable them to write new apps that integrate augmented and virtual reality into our everyday lives.
Earlier in 2018 Arm introduced you to Mali-G52 Mainstream GPU, and the premium Mali-G76 is based on the same iteration of the Bifrost graphics architecture. The wider cores enable far greater compute performance throughout the pipeline by providing twice the compute performance in much less than twice the silicon area. Not only does this provide the performance density gains but it also contributes greatly to the energy efficiency numbers by amortising the overhead of the shared logic across the larger number of execution lanes and reduces the cost of the overall SoC.
Another feature is the introduction of int8 dot product support. This is the element that has the greatest effect on ML performance.
Mali-G76 also benefits from a dual texture mapper, providing twice the throughput of the Mali-G72, and therefore a huge leap in efficiency. This means far longer sustained performance for power-hungry high-end graphics use cases.
In another bid to improve both performance density and power consumption, Arm's designers have optimized the registers using half the number of register banks but in a larger size, which improves both area and energy efficiency.
Preloading optimisations
Varying preload at sample locations has traditionally presented something of a problem, in that varying interpolation is normally done at the pixel center, but if sample-frequency shading is enabled, varying interpolation is done at the sample location. This meant the compiler had to encode the interpolation location within the instruction, not knowing if sample-frequency shading will be used or not and thereby having to output two different shader variants. Arm has addressed this by ensuring that the compiler can use the same sequence for either sample or centre variants, which means only one shader variant is required, improving the energy efficiency of the GPU.
When the the depth buffer has to be preloaded, pre-frame shaders that use the texture mapper to fetch depth values and output these to the tile buffer are issued, but fetching these depth values takes more time than is optimal due to the inherent memory latency, which can cause dependency stalls in the GPU.
Complex applications using multi-render targets and no MSAA tend to run out of colour tile buffer space before tile depth buffer, meaning we have spare tile depth buffers. With Mali-G76, Arm allocates this tile depth buffer space as early as possible and run the depth preload. If they run early enough, then depth preload is complete by the time normal fragments are produced therefore avoiding dependency stalls. This improves GPU performance for complex content.
Cache improvements
Thread Local Storage (TLS) is an area of the stack used for register spilling in shaders. Mali-G76 implements TLS address interleaving, enabling data for a single thread to be grouped together at the same location in the cache, whereas previously data could be in smaller amounts and in several locations. Retrieving data from a single location is more efficient and improves overall compute performance.
Ordered writeback in the tiler can cause stalls when there is a miss in the - TLB (Translate Lookaside Buffer). In Mali-G76 Arm has implemented Out of order polygon list writeback, allowing the GPU to continue executing while the cache miss is resolved. This helps Mali-G76 scale to larger capabilities than any of our previous generation GPUs.
Arm also claims that the Mali G76 delivers at 7 nm an estimated 50% overall improvement compared to the existing G72 made in a 10-nm process.
Mali-V76
The Mali-V76 supports 8K decode up to 60fps or four 4K streams at 60fps giving consumers the opportunity to stream four movies, record video while video conferencing, or watch four games in 4K. And at lower resolutions, and still at full HD, Mali-G76 will support up to 16 streams of content, creating a 4x4 video wall.

2020 is when Japan is due to host the Olympics, and they promise Full 8K coverage. So, devices powered by the Mali-V76 video processor will be ahead of the curve in supporting the Super High Vision (SHV) format.
An 8K60 stream needs 4x the bandwidth of a 4K60 stream, so by adding an extra AXI bus, Arm doubled the throughput capability on one side. Arm also doubled the line buffers from 4096 to 8192 throughout the video pipeline. A line buffer literally handles a line of pixels, so as you might assume, an 8K line is twice the width of a 4K one, delivering the extra boost.
In addition, for the first time Mali-V76 is also able to handle 8K encode, though only at 30fps at this stage.
As an alternative to one 8K stream, you could instead support four 4K streams at 60fps, rolling previews of up to four different shows at once. With lower resolution content, you can show an even greater variety of viewing options with up to 16 streams running in the still very impressive Full HD. This ability to support a 4x4 video wall is increasingly becoming an absolute essential in the Chinese market.

Through seamless integration of firmware and hardware, Arm says that the Mali-V76 achieves a whopping 25% improvement on encode quality compared to Mali-V61, and these firmware improvements have brought an additional 5% when compared to the Mali-V52 mainstream VPU.
As data is streamed into the display pipeline it moves through a display processor like the Mali-D71 and into the Assertive Display processor. Arm's Assertive Display 5 then reads the characteristics of the previously handled frame and applies any necessary fixes to the next frame. Of course, one frame passes in the blink of an eye, but even in such a brief moment, the human eye and brain can detect inconsistencies. So, at the end of a movie, if it switches to the black-screen credits or from a bright and sunny outdoor scene, for example, the visual balance is momentarily wrong. The eye will interpret this one frame delay the Assertive Display processor takes to figure it out as a tiny flicker, small but perceptible.

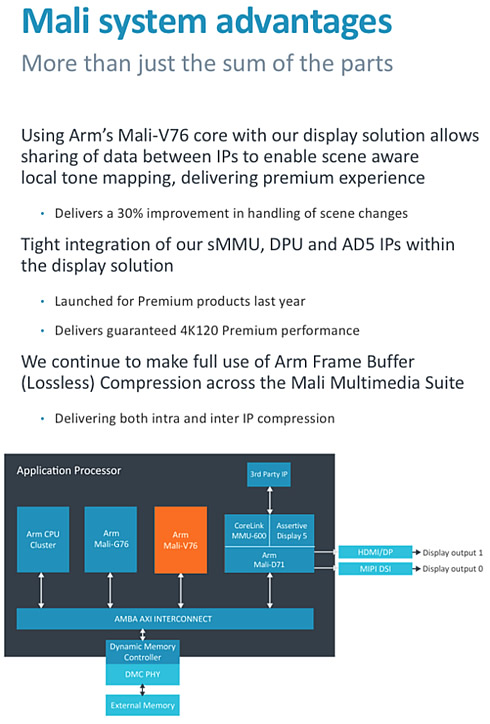
However, in communications between Mali-V76 and Mali-D71, a huge number of statistics are gathered through the decoding process, and these statistics are very similar to those used by Assertive Display 5 to establish what it needs to change. To make the most effective use of this similarity, Arm created a link in Mali-V76 that will feed into Mali-D71 and provide those stats at the same time it provides the frame itself. This means Assertive Display 5 no longer needs to redo the work and can instead apply the knowledge directly to the very same frame. Even at 60 or 120fps, this smooths out many visual artefacts you may not even have been aware of, raising the visual quality beyond even the bounds of resolution and framerate improvements.
Arm Cortex-A76 CPU
| Architecture | Armv8-A (Harvard) | |
| Extensions |
|
|
| ISA support |
|
|
| Microarchitecture | Pipeline | Out-of-order |
| Superscalar | Yes | |
| NEON / Floating Point Unit | Included | |
| Cryptography Unit | Optional | |
| Max number of CPUs in cluster | Four (4) | |
| Physical addressing (PA) | 40-bit | |
| Memory system and external interfaces | L1 I-Cache / D-Cache | 64KB |
| L2 Cache | 256KB to 512KB | |
| L3 Cache | Optional, 512KB to 4MB | |
| ECC Support | Yes | |
| LPAE | Yes | |
| Bus interfaces | AMBA ACE or CHI | |
| ACP | Optional | |
| Peripheral Port | Optional | |
| Other | Functional Safety Support | ASIL D |
| Security | TrustZone | |
| Interrupts | GIC interface, GIVv4 | |
| Generic timer | Armv8-A | |
| PMU | PMUv3 | |
| Debug | Armv8-A (plus Armv8.2-A extensions) | |
| CoreSight | CoreSightv3 | |
| Embedded Trace Macrocell | ETMv4.2 (instruction trace) |
Arm Mali-G76 GPU
| Anti-Aliasing | 4x MSAA 8x MSAA 16x MSAA |
4x Multi-Sampling Anti-Aliasing (MSAA) with minimal performance drop. |
| API Support | OpenGL ES 1.1, 2.0, 3.1, 3.2 Vulkan 1.1* OpenCL 1.1, 1.2, 2.0 Full Profile |
Full support for next-generation and legacy 2D/3D graphics applications. |
| Bus Interface | AMBA4 ACE-LITE |
Compatible with a wide range of bus interconnect and peripheral IP. |
| L2 Cache | Configurable 512KB - 4MB |
2 or 4 slices. |
| Scalability | 4 to 20 Cores | Configurable form 4 to 20 cores delivering largest capability for a Mali GPU. |
| Adaptive Scalable Texture Compression (ASTC) |
Low Dynamic Range (LDR) and High Dynamic Range (HDR). Supports both 2D and 3D images. |
ASTC offers a number of advantages over existing texture compression schemes by improving image quality, reducing memory bandwidth and thus energy use. |
| Arm Frame Buffer Compression (AFBC) | Version 1.2 4x4 pixel block size |
AFBC is a lossless image compression format that provides random access to pixel data to a 4x4 pixel block granularity. It is employed to reduce memory bandwidth both internally within the GPU and externally throughout the SoC. |
Arm Mali-V76
| Features | Value | Description |
| Codec Support | For encode and decode: VP9 Profile 2 (10-bit) and Profile 0 (8-bit), HEVC Main 10 and Main, H.264 Hi10P/HP/MP/BP, VP8, JPEG. Decode only: MPEG4, MPEG2, VC-1/WMV, Real, H.263, AVS+/AVS. |
Driver and video streaming infrastructure based on OpenMAX IL, which runs on the host CPU. |
| Bus Interface | AMBA4 AXI | Compatible with a wide range of bus interconnect and peripheral IP. |
| Memory System | MMU | Built-in Memory Management Unit (MMU) to support virtual memory. |
| Performance | 1080p 60 to 4K120 | Scalable from one to four cores with multiple performance points. |