New Arm Neoverse N1 and E1 Platforms Boost Infrastructure Performance
Arm has announced the Arm Neoverse N1 and E1 platforms, designed for faster time-to-market and optimal design points for cloud to edge applications in the era of 5G.
Arm’s vision with Neoverse, announced last October, is about more than just processor IP. It is about delivering a complete infrastructure platform and the elements required to enable an ecosystem of software, SoCs, systems, and tools for compelling new solutions from the cloud data center to the 5G edge.
Arm Neoverse N1: Accelerating the transformation to a scalable cloud to edge infrastructure

The Neoverse N1 platform is the first compute platform from Arm capable of servicing the wider range of data center workloads with performance levels competitive with the legacy architectures used in the public cloud.
The Neoverse N1 i spart of a roadmap committed to delivering more than 30% higher performance per generation. Arm says that the performance of N1 substantially overdelivered, with at least 60% and higher performance increases and a2.5x more performance on key cloud workloads over the Cortex-A72 based Cosmos platform at the same frequency.

Going beyond raw compute performance, the Neoverse N1 platform was built from the ground up with infrastructure-class features including server-class virtualization, RAS support, power and performance management, and system level profiling. The platform also includes a coherent mesh interconnect, power efficiency, and a compact design approach for tighter integration, enabling scaling from 4- to 128-cores. Arm says that this scalability will gibe its partners the flexibility to build diverse compute solutions by adding accelerators or other features with their own on-chip custom silicon.
The Neoverse N1 is primarily optimized for high performance, but also designed for efficiency, achieving a 30% power efficiency increase over Cortex-A72 in the same process. The N1 is a 64b CPU with support for Aarch32 at user level, which delivers benefits for applications like running Android workloads in the cloud.
Every facet of the N1 design has been optimized for sustained performance. The pipeline is an 11-stage accordion pipeline, which shortens in the presence of branch misses, and lengthens in normal operation. It uses a 4-wide front-end, with 8-wide dispatch/issue, three full 64-bit integer ALUs and a dedicated branch unit. The Neon Advanced SIMD pipeline is substantially wider, with dual 128b data paths. The ability to feed the SIMD engine is also widened substantially to dual 128-bit load / store pipeline with decoupled address/data, enabling sustained 2x128 performance.


The SIMD unit is designed to enable vector processing without the frequency throttling seen on legacy architectures in the data center. The combination of 2x128 SIMD with unthrottled performance and >2x core count vs. the competition enables scale-out vector performance. Arm claims that the design achieves 95% compute efficiency on compute dense workloads using Arm optimized math libraries. It also shows up to 6x gains in machine learning workloads utilizing an 8-bit dot product instruction. Hyperscalers are increasingly using “free” CPU ML capability during lower loading cycles in non-peak use times, and generally for inference workloads in the cloud.
The Neoverse N1 caching structures are sized for large, branch-heavy infrastructure workloads, starting with 64K L1I/D, out through low-latency private 512K/1MB L2 caches, and backed by up to a 64-bank 128M system-level cache.
Continuing through the front end, the branch predictor includes a 6K Branch Target Buffer, 5K+8K direction predictors, and a high-capacity hybrid indirect-branch predictor. Page translation is sped up by 48-entry instruction and data L1 TLBs, and backed by a 1280-entry L2 TLB. The Neoverse N1 is the first Arm CPU with coherent I-cache, critical for performance on large-scale many-core systems. The N1 has been optimized for accelerating Type1 and Type 2 hypervisors and minimized the setup/teardown overhead of VM and container switching and migration.
The overall memory hierarchy is designed from top to bottom for low latency, high bandwidth, and scalability. This is evidenced by features like predict-directed-fetch front-end, 46 outstanding system-transactions, 32 outstanding non-prefetch transactions, and 68 in-flight LDs, 72 in-flight STs. The system cache features 22ns load to use in typical system, 1TB/s bandwidth, and supports DRAM-target prefetch to manage bandwidth utilization.
The N1 uses a flexible high-performance coherent mesh interconnect with advanced routing, memory and caching features, supporting on-chip or off-chip fully coherent acceleration over CCIX. The platform is supported by an ecosystem of deployment ready v8.2 software, with the same software across all configurations.
The design features a comprehensive RAS architecture, including write-once error-handler software, and kernel support with ServerReady compliance. ServerReady enables cloud operators to certify that their Arm servers will boot and run in a standard way in their environment, just like any other server. The RAS architecture supports consistent and architected error-logging with increased resilience/availability with full-system data poisoning at double word (64b) granularity, carried throughout system and cache-hierarchy. No error is exposed until/unless poisoned data is actually consumed. The design employs a consistent error-injection microarchitecture enabling qualification of error-handlers, with SECDED ECC protection on caches.
The N1 platform supports Armv8.2 Virtual Host Extensions (VHE), with scalability up to 64K VMs, to avoid exception level transitions for Type 2 hypervisors (e.g. KVM). The virtualization implementation in the N1 features latency-optimized hyper-traps, to minimize world-switch overhead. The MMU is optimized for virtualized nested paging, and the design is optimized for heavy OS/Hypervisor activity with low-latency switching, high-bandwidth context save/restore, and minimized context-synchronization serialization. This maps well to the VM-based and containerized workloads in cloud datacenters and modern virtualized network equipment.
The design features intelligent performance management, with a per-core activity monitoring unit (AMU) enabling fully-informed DVFS/DFS thread management. The design also includes features for active mitigation of power-virus scenarios, where hardware throttling reduces virus conditions to ~TDP levels, with negligible performance impact across non-virus workloads. This enables designers to build SoC power-delivery network to TDP conditions, not virus conditions.
The Neoverse N1 has been designed to unleash performance in large-scale systems (64+ cores), while also scaling down to as few as 8 cores in edge designs.
The power efficiency results in TDP headroom that enables high-core-count, unthrottled performance for designs that scale from 64 to 128 N1 cores within a single coherent system. The system itself can scale beyond that, however real systems will architect around memory bandwidth and likely come in at 64 to 96 cores with 8ch DDR4 and 96 to 128 cores with DDR5. Designers can employ chiplets over CCIX links for cost-effective manufacturability. The Neoverse N1 is scalable, enabling the industry’s highest core count at 128 cores for hyperscale down to 8 cores for edge with power ranging from <200W to <20W. Not only can you scale to high core counts, but the compact design, coherent mesh interconnect, and industry leading power efficiency of the Neoverse N1 give our partners the flexibility to build diverse compute solutions by using the available silicon area and power headroom to add accelerators or other features with their own custom silicon.
Arm Neoverse E1: Empowering the infrastructure to meet next-generation throughput demands
The Neoverse E1 platform was designed to enable the transition from 4G to a more scalable 5G infrastructure with more diverse compute requirements. Featuring an intelligent design for highly-efficient data throughput, the Neoverse E1 achieves 2.7x more throughput performance, 2.4x more throughput efficiency, and over 2x more compute performance compared to Arm's previous generations. It also delivers scalable throughput for edge to core data transport, supporting everything from a sub-35W base station all the way through to a multi-100GB router.
Arm says that the microarchitecture for Neoverse E1 was developed around two design goals: maximizing throughput while balancing compute and efficiency requirements. The Neoverse E1 offers 2.7x throughput performance with 2.4x throughput-to-power efficiency and 2.1x compute performance over the popular Cortex-A53. Its impressive compute and throughput performance in a highly efficient package allow for deployment in locations where power is limited, and where general-purpose server processors do not fit. For example, using Neoverse E1 in an 8-core Power-over-Ethernet (PoE) driven wireless access device or low-power 5G edge transport node would be ideal use cases. In addition, the highly flexible and scalable architecture of Neoverse E1 allows the platform to scale up to multi-port 100Gbps devices like a firewall appliance.

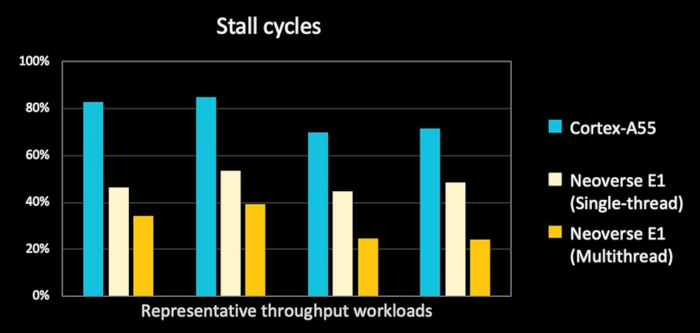
For throughput workloads, Arm investigated the system behavior and found that cache misses dominate up to 80% of processing cycles on a conventional small core, high efficiency processor like Cortex-A53 or Cortex-A55. This means during cache misses, the core is stalled waiting for data to become available. One method to address this inefficiency is the out-of-order pipeline in the Neoverse E1 microarchitecture. This allows the instructions that do not depend on the missing data to execute ahead and reduces the stall cycles down to 50%. However, the design approach taken in the Out-of-Order design is consistent with highly efficient core design, for example limiting the reorder buffer to 40 instructions, and the reservation stations to 8 entries – providing the benefit of out of order issue and retire, with the power and area cost of a long OoO window.
Arm engineers also incorporated simultaneous multithreading (SMT) into the design. The Neoverse E1 can process two threads concurrently resulting in higher aggregated system throughput and improved efficiency. From a software perspective, the two threads appear as two individual CPUs. They can be at different exception levels and running different operating systems altogether. SMT lowers the stall cycle in throughput workloads to 30% on typical throughput workloads, a big reduction from the 70~80% achieved on Cortex A-55 without OoO and SMT.
Additional infrastructure features that help improve the throughput performance are cache stashing and the Accelerator Coherency Port (ACP). The ACP allows an accelerator to have low latency, closely coupled tie into the processor cluster. An accelerator agent can utilize cache stashing feature by sending a cache stashing hint to send the data into each core’s private L2 cache or the cluster L3 cache making the data available to the CPUs before an instruction need them. This in effect reduces the number of cache misses and the overall latency.
To demonstrate the performance of the Neoverse E1 platform, Arm developed a 5G small cell transport software prototype which simulates packet processing workloads at a 5G base station. The simulated device would process data packets in two directions – from the wireless interface upstream to an aggregator or edge cloud (uplink), and on the opposite downlink direction. The prototype runs on Linux operating system and utilizes several open-source libraries such as Data Plane Development Kit (DPDK) and OpenSSL.
For uplink processing, the device must translate cellular packets received from the cell tower to IP packets, perform IPsec encryption, and process the packets according to the network rules which may include fragmenting larger packets into smaller pieces. Since Neoverse E1 can process the data in parallel across multiple threads/cores, the software needs to reorder the egress packets to have the same sequence as at ingress.
On the other hand, the device must reassemble the encrypted IP packets receiving from the edge cloud and perform decryption before converting them to cellular packet suitable for radio transmission. Packet reordering also applies in this direction.
With this software prototype of a 5G base station, Arm put the Neoverse E1 Edge Reference Design through its paces. The Neoverse E1 Edge Reference Design includes sixteen Neoverse E1 cores arranged in two clusters of eight cores, connected through the high-performance CMN-600 mesh interconnect, MMU-600 system MMU, and 2-channel DDR4-3200.
According to Arm, the Neoverse E1 Edge Reference Design reaches more than 50Gbps aggregated throughput on all-software packet processing. In term of power, the Neoverse E1 cores in the Edge Reference Design consume less than 4W at 2.3GHz. This is significant because power availability at the edge of the network is very limited; usually less than 15W is available for SOC power budget. Less CPU power consumption means more power is available for other peripherals such as radio, DSP or other accelerators.
When the requirement calls for both control plane and data plane functionalities in the same device, the Neoverse E1 can provide generous compute performance for light control plane tasks. In a multi-cluster Neoverse E1 design, a single cluster for control plane workloads can be set aside while the rest of the Neoverse E1 clusters are dedicated to the data plane. Fixed-function accelerators, such as crypto engine, can tie into the cluster via ACP to offload and shorten the packet processing time.
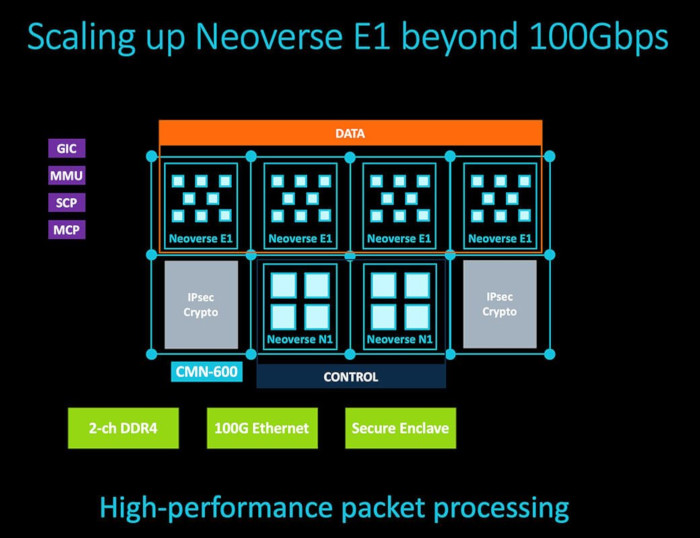
Neoverse E1 and Neoverse N1 processors can be also combined in a heterogenous design for high-performance systems. The Neoverse N1 clusters are assigned to the control plane and the Neoverse E1 clusters are used for data plane functions in this scenario. Some of the example devices utilizing this kind of system are firewall appliances with deep packet inspection and intrusion detection capabilities, multi-100Gbps routers and SmartNICs.