AMD, ARM, Huawei, IBM, Mellanox, Qualcomm, Xilinx Unite To Form CCIX Accelerator Consortium
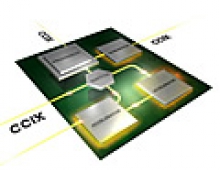
Seven technology companies have reached an agreement to develop and implement an interconnect that would enable different vendors’ CPUs and accelerators to talk to one another while sharing main memory. Advanced Micro Devices (AMD), ARM Holdings , Huawei Technologies, IBM, Mellanox, Qualcomm and Xilinx on Monday announced that they would collaborate to build a cache-coherent fabric to interconnect their CPUs, accelerators and networks.
The companies will try to build a cache coherent interface between homogeneous chips like CPUs. Building one that allows devices to share data across disparate implementations of CPUs, FPGAs, GPUs and network chips.
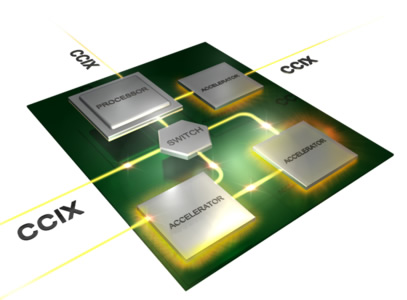
Engineers have been looking at accelerators such as GPUs, FPGAs, DSPs and network offload engines to continue to keep up with the market demand for cheaper and faster computing. Today’s accelerators typically connect to the processor via PCIe (PCI Express), which is generally slow.
The difficult task is to making the CPU and a number of accelerators all behave equally on a shared memory bus or fabric, and share access to high speed memory that is "cache-coherent" to ensure tha avery part retrieves the same value from a memory location.
If the companies succeed, importand benefits will include plug-and-play compute and network acceleration for any processor, as well as higher performance and lower application latency.
IBM and NVIDIA have also developed their own technologies to address the same cashe issues. With POWER8, IBM announced the Cache-Coherent Accelerator Processor Interconnect, or CAPI, which is now being used by Xilinx to improve performance.
NVIDIA has invested in NVLink, which provides faster connectivity between GPUs and with IBM POWER.