Research Project Can Interpret, Caption Photos
Microsoft researchers are working on a technology that can automatically identify the objects in a picture, interpret what is going on and write an accurate caption explaining it. "The machine has been trained to understand how a human understands the image," said Xiaodong He, a researcher with Microsoft Research’s Deep Learning Technology Center and one of the people working on the project.
For example, when given a picture of a man sitting in front of a computer, the image captioning technology can accurately recognize that it should focus on describing the man in the foreground, not the image on the computer in the background. Because the man has facial hair, it also knows that it is a man, not a woman.
The system is based on neural networks, which are computing elements that are modeled loosely after the human brain, to connect vision to language. With that technology, the systems began to get it right more often, and error rates have been decreasing ever since.
Automated image captioning still isn’t perfect, but it has quickly become a hot research area, with experts from universities and corporate research labs vying for the best automated image captioning algorithm.
The latest competition to create the most informative and accurate captions, the MS COCO Captioning Challenge 2015, ends this Friday.
Throughout the competition, a leaderboard has been tracking how well the teams are doing using various technical measurements, and ranking them based on who is currently producing the best results.
The competitors are all using a dataset of images, called Microsoft COCO, which was developed by researchers from Microsoft and other research institutions. The challenge is to come up with the best algorithm that creates captions based on that dataset.
Microsoft’s algorithm is trained to automatically write a caption using several steps.
First, it predicts the words that are likely to appear in a caption, using what’s called a convolutional neural network to recognize what’s in the image.
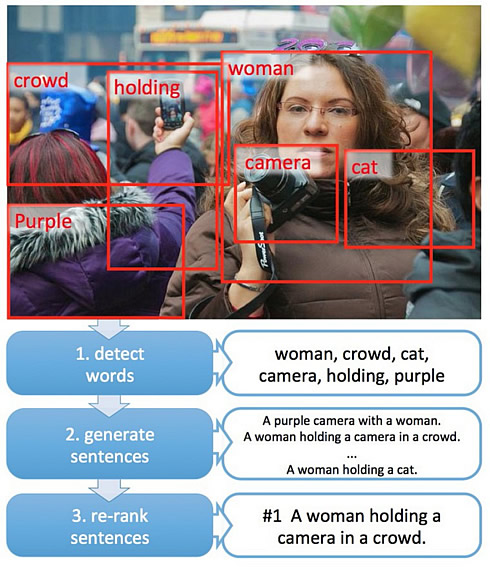
The convolutional neural network is trained with many examples of images and captions, and automatically learns features such as color patches, shapes and other features. That’s much like the way the human brain identifies objects.
Next, it uses a language model to take that set of words and create coherent possible captions.
"The critical thing is that the language model is generating text conditioned on the information in the image," said Geoffrey Zweig, who manages Microsoft Research’s speech and dialog research group.
Finally, it deploys a checker that measures the overall semantic similarity between the caption and the image, to choose the best possible caption.
As the technology continues to improve, the researchers say they see vast possibilities for how these types of tools could be used to make significant gains in the field of artificial intelligence, in which computers are capable of intelligent behavior in an era of more personal computing.
The goal is to connect vision to language in order to have artificial intelligence tools.
Recently, Stephen Wolfram, the brain behing Mathematica, has also talked about a function called ImageIdentify built into the Wolfram Language that lets you ask, "What is this a picture of?" - and get an answer.