Fujitsu Streamlines AI Video Recognition with Compression Technology
Fujitsu Laboratories Ltd. has developed a technology for compressing ultra-high-definition, high-volume video data to the minimum size needed for AI video recognition applications.
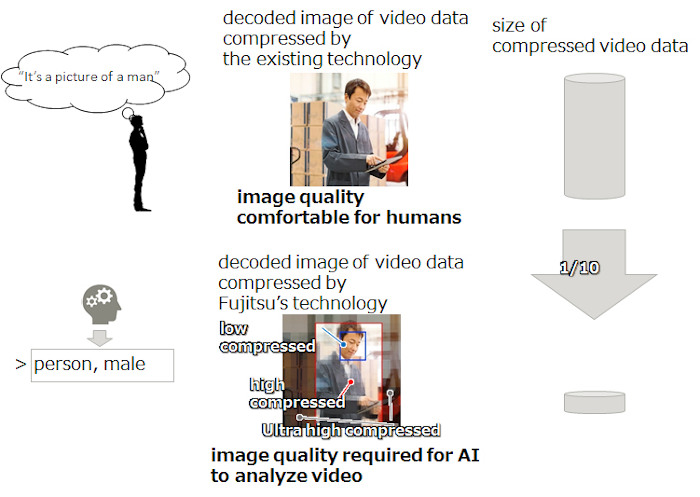
This technology can compress video data to just one tenth the size of data prepared using conventional compression technology intended for visual confirmation by humans.
In developing this new compression technology, Fujitsu focused on an important divergence in the way in which AI and humans recognize images. Namely, AI and humans tend to differ in the areas of the image that are emphasized as important for judgment when recognizing people, animals, or objects in video data. Fujitsu has developed a technology to automatically analyze the areas that AI values and to compress data to the minimum size that AI can recognize. This makes it possible to analyze a large amount of video data without compromising recognition accuracy, and at the same time significantly reduce operating and data transmission costs. It is also anticipated that the technology will allow users to analyze more advanced video data by combining multiple video data stored in the cloud, sensor data, and performance data such as sales data.
About the new technology
Compressing video reduces image quality depending on the compression rate, and if the area that AI is focused on is compressed excessively, the recognition accuracy decreases. Fujitsu's video compression technology automatically analyzes the area of an object recognized by AI as judgment material in an image of 1 frame of video data, compressing (H. 265/HEVC) the image with the minimum image quality required for recognition for each area. By applying this technology, the size of video data can be significantly reduced compared with conventional compression technologies while maintaining recognition accuracy.
The effect of image quality degradation specific to compression on recognition accuracy is analyzed for each area. The compression ratio that does not affect recognition accuracy is automatically estimated based on the AI recognition results.
The degree of importance of features in the process of recognition by AI is determined for all areas by aggregating the effects on the recognition results when the compression ratio of the entire image is changed and the image quality is changed. The compression rate immediately before the recognition accuracy rapidly deteriorates in each area is estimated as a compression rate that does not affect the recognition accuracy.
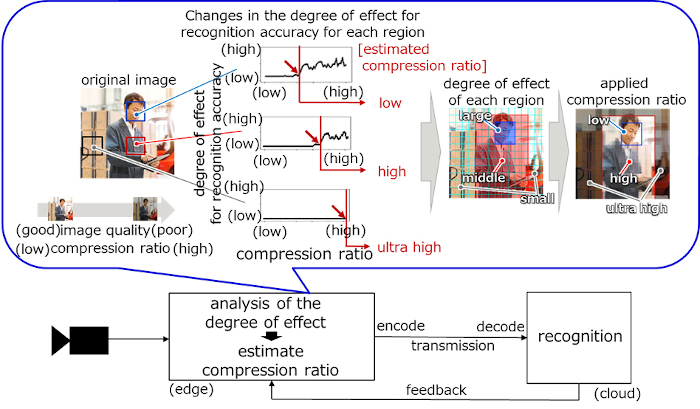
It also feeds back the AI results of successive images to increase the compression to the maximum AI can recognize. In so doing, the technology achieves high image compression while maintaining AI recognition accuracy.
The new technology was applied to video footage taken by a 4K camera of multiple workers packing in a factory. It was confirmed that the data size could be reduced to 1/10 the data size of conventional compression technology without a deterioration in recognition accuracy. This technology is expected to be used for applications that do not require strict real-time performance, as well as for the analysis of advanced video data that combines multiple video data stored in the cloud, sensor data, and performance data such as sales data.
Fujitsu Laboratories is evaluating this technology in a variety of cases, and is carrying out additional research and development to further refine compression performance. Fujitsu expects to commercialize this technology by the end of fiscal 2020, and introduce it into a variety of applications for different industries, including its Fujitsu Manufacturing Industry Solution COLMINA service platform .