IBM Sets Tera-scale Machine Learning Benchmark Record with POWER9 and GPUs
At IBM THINK in Las Vegas, IBM reported a breakthrough in AI performance using new software and algorithms on optimized hardware, including POWER9 with NVIDIA V100 GPUs.
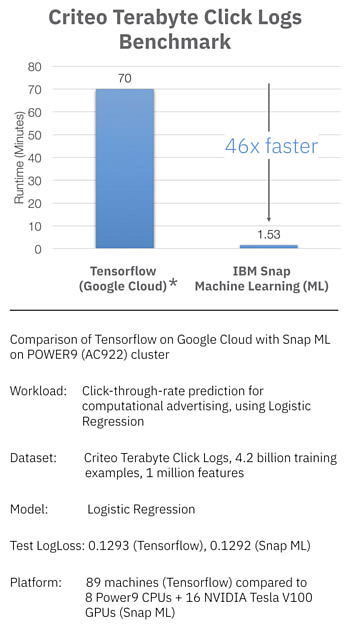
In a newly published benchmark, using an online advertising dataset released by Criteo Labs with over 4 billion training examples, IBM researchers trained a logistic regression classifier in 91.5 seconds. This training time is 46x faster than the best result that has been previously reported, which used TensorFlow on Google Cloud Platform to train the same model in 70 minutes.
The AI software behind the speed-up is a new library developed over the past two years by IBM's team at IBM Research in Zurich called IBM Snap Machine Learning (Snap ML) - because it trains models faster than you can snap your fingers.
The library provides high-speed training of popular machine learning models on modern CPU/GPU computing systems and can be used to train models to find new and interesting patterns, or to retrain existing models at wire-speed (as fast as the network can support) as new data becomes available.
The adoption of machine learning and artificial intelligence has been, in part, driven by the ever-increasing availability of data. Large datasets enable training of more expressive models, thus leading to higher quality insights. However, when the size of such datasets grows to billions of training examples and/or features, the training of even relatively simple models becomes prohibitively time consuming.
IBM claims that Snap ML is not only for large data applications where training time can become a bottleneck. For example, real-time or close-to-real-time applications, in which models must react rapidly to changing events, are another important scenario where training time is critical. For instance, consider an ongoing hack threatening the energy grid, when a new, previously unseen, phenomenon is currently evolving. In such situations, it may be beneficial to train, or incrementally re-train, the existing models with new data on the fly. One's ability to respond to such events necessarily depends on the training time, which can become critical even when the data itself is relatively small.
A third area when fast training is highly desirable is the field of ensemble learning. It is well known that most data science competitions today are won by large ensembles of models. In order to design a winning ensemble, a data scientist typically spends a significant amount of time trying out different combinations of models and tuning the large number of hyper-parameters that arise. In such a scenario, the ability to train models orders of magnitude faster naturally results in a more agile development process. A library that provides such acceleration can give its user a valuable edge in the field of competitive data science or any applications where best-in-class accuracy is desired. One such application is click-through rate prediction in online advertising, where it has been estimated that even 0.1% better accuracy can lead to increased earning of the order of hundreds of millions of dollars.
According to IBM, the three main features that distinguish Snap ML are:
- Distributed training: IBM builds its system as a data-parallel framework, enabling the company to scale out and train on massive datasets that exceed the memory capacity of a single machine which is crucial for large-scale applications.
- GPU acceleration: IBM implements specialized solvers designed to leverage the massively parallel architecture of GPUs while respecting the data locality in GPU memory to avoid large data transfer overheads. To make this approach scalable, the comapany takes advantage of recent developments in heterogeneous learning in order to enable GPU acceleration even if only a small fraction of the data can indeed be stored in the accelerator memory.
- Sparse data structures: Many machine learning datasets are sparse, therefore IBM employs some new optimizations for the algorithms used in teh IBM system when applied to sparse data structures.
The Terabyte Click Logs is a large online advertising dataset released by Criteo Labs for the purposes of advancing research in the field of distributed machine learning. It consists of 4 billion training examples.
Each example has a "label", that is, whether or not a user clicked on an online advert, and a corresponding set of anonymized features. The goal of machine learning for such data is to learn a model that can predict whether or not a new user will click on an advert. It's one of the largest publicly available datasets. The data was collected over 24 days, and on each day they collected on average 160 million training examples.
In order to train on the full Terabyte Click Logs dataset, IBM deployed Snap ML across four IBM Power System AC922 servers. Each server has four NVIDIA Tesla V100 GPUs and two Power9 CPUs which communicate with the host via the NVLINK 2.0 interface. The servers communicate with each other via an Infiniband network. When training a logistic regression classifier on such infrastructure, IBM achieved a test loss of 0.1292 in 91.5 seconds.
The closest result to Snap ML in terms of speed was reported by Google, who deployed TensorFlow on their cloud platform to train a logistic regression classifier in 70 minutes. They report using 60 workers machines and 29 parameter machines. Relative to the TensorFlow results, IBM says that Snap ML achieves the same loss on the test set but 46x faster.
When deploying GPU acceleration for such large scale applications one main technical challenge arises: the training data is too large to be stored inside the memory available on the GPUs. Thus, during training, data needs to be processed selectively and repeatedly moved in and out of the GPU memory. To profile the runtime of the application IBM analyzes how much time is spent in the GPU kernel vs. how much time is spent copying data on the GPU. For this study IBM used a smaller subset of the Terabyte Clicks Logs, consisting of the first 200 million training examples, and compare two hardware configurations:
- An Intel x86-based machine (Xeon Gold 6150 CPU @ 2.70GHz) with 1 NVIDIA Tesla V100 GPUs attached using the PCI Gen 3 interface.
- A IBM POWER AC922 server with 4 NVIDIA Tesla V100 GPUs attached using the NVLINK 2.0 interface (we only use 1 of them for comparison).
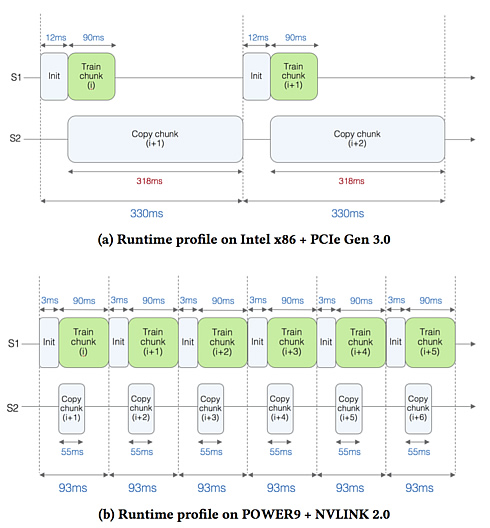
In the above figure, IBM shows the profiling results for the x86-based setup. You can see two streams S1 and S2. On stream S1, the actual training is being performed (i.e., calls to the logistic regression kernel). The time to train each chunk of data is around 90 milliseconds (ms). While the training is ongoing, in stream S2 we copy the next data chunk onto the GPU. It takes 318 ms to copy the data, thus meaning that the GPU is sitting idle for quite some time and the copy time is clearly the bottleneck.
In the next figure, for the POWER-based setup, we observe that the time to copy the next chunk onto the GPU is reduced significantly to 55 ms (almost a factor of 6), due to the faster bandwidth provided by NVLINK 2.0. This speed-up hides the data copy time behind the kernel execution, effectively removing the copy time from the critical path and resulting in a 3.5x speed-up.
This IBM Research breakthrough will be available for IBM's customers to try as part of the PowerAI Tech Preview portfolio later this year.
Deep Learning as a Service
Seperately, IBM introduced Deep Learning as a Service within Watson Studio, a set of cloud-based tools for developers and data scientists to help remove the barriers of training deep learning models in the enterprise.
Deep learning, in particular, requires users to be experts at different levels of the stack, from neural network design to new hardware.
IBM says that Deep Learning as a Service within Watson Studio make strides in addressing challenges and increasing the productivity of data scientists and software engineers, as well as the quality and maintainability of their AI creations.
The Deep Learning as a Service architecture spans several layers, including hardware accelerators, open source DL frameworks, Kubernetes for container orchestration, and services to manage and monitor the training runs.
Many teams working with deep learning models involve people who don't spend their time on data science tasks, but on configuring esoteric hardware, installing drivers, managing distributed processes, dealing with failures, or figuring how how to fund the money to buy specialized hardware, such as GPUs. IBM wants to let users continue to design their models in the framework of their choice, but train them in an optimized hardware and software stack offered as a managed cloud service.
Determining the parameters of a neural-network effectively is a challenging problem due to the extremely large configuration space (for instance: how many nodes per layer, activation functions, learning rates, drop-out rates, filter sizes, etc.) and the computational cost of evaluating a proposed configuration (e.g., evaluating a single configuration can take hours to days). To address this challenging problem IBM uses a model-based global optimization algorithm called RBFOpt that does not require derivatives. Similarly to Bayesian optimization - which fits a Gaussian model to the unknown objective function - IBM's approach fits a radial basis function model.
Machine learning models are increasingly at the core of applications and systems. The process around developing these models is highly iterative and experiment-driven. The often non-linear and non-deterministic nature of implementing ML models results in a large number of diverse models. Data scientists tend to manage models using ad hoc methods such as notebooks, spreadsheets, file system folders, or PowerPoint slides. However, these ad hoc methods record the models themselves, but not the higher-level experiment. As a result, a data scientist?s dashboard emerged that IBM refined continuously with its internal end users to arrive at the current design with the product teams. This dashboard allows data scientists to compare versions of models across experimental runs and to visually see how each individual parameter affects the resulting accuracy of the model. The system can also display samples of the input data, plot accuracy/loss curves for the individual runs, and do provenance tracking of the model's data and code artifacts.
IBM researchers are also trying to instill a visual programming paradigm for deep learning. The rate at which the domain of deep learning is growing is faster than the rate at which developers or software engineers can be trained to build applications using deep learning. The company developed a visual programming paradigm using drag and drop interface, and provided a platform agnostic representation for capturing deep learning model design / architecture.
In the labs, IBM is experimenting with expediting the creation of neural nets through Auto-generation of Code from Deep Learning Research Papers.
The Power of Power9 servers
In the more traditional server space, IBM is trying to promote systems based on the Power 9 processor as an x86 alternative.
Google, an early partner in IBM's Open Power initiative, announced it is expanding its tests of Power 9 systems, and hopes to move at least some Power systems into production use this year.
China's Alibaba and Tencent also are testing Power 9. Tencent said Power 9 is delivering 30 percent more performance than the x86 while using fewer servers and racks.
IBM's corporate aim is to win within four years at least 20 percent of the sockets for Linux servers sold for $5,000 or more. IBM's Power roadmap calls for annual processor upgrades in 14nm through 2019 and a Power 10 slated for some time after 2020--leaving room for a possible 7nm chip in 2020, shown two years ago.
Power 9 should do better than its predecessors given its costs, bandwidth and ease of porting. Power 9 is IBM's first to use standard DIMMs, opening a door to other standard components that are overall cutting system costs by 20 to 50 percent compared to the Power 8, IBM's partners said.
The proprietary NVLink 2.0 that can connect Power 9 to multiple Nvidia Volta GPUs provides a bandwidth edge over the x86. Many of the new Power 9 systems aim to leverage the Nvidia GPU's dominance in training neural networks to win adoption in large data center operators for AI jobs.
One of three areas where Google sees promise for Power 9 is as a superior host teamed up with an accelerator such as its TPU. Power 9 also supports many cores and threads, factors closely tied to performance on Google search tasks, said Maire Mahony, a Google system engineer who serves as treasurer for the Open Power Foundation.




















